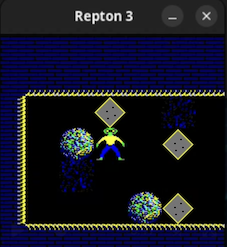
 My version of Repton running in its dinky window (watch video)
My version of Repton running in its dinky window (watch video)I’ve been involved in a funny story of retro games and broken encryption going back several decades. In case you’re not interested in the Repton 3 game, I’ll skip ahead to…
the broken encryption bit
…because there’s an important lesson here. Do not roll your own encryption!
As a 19 year old computing student I’m not sure if I had yet started learning about encryption on my course, but either way I should’ve known better.
I made a feature of my game, to allow creating “locked” levelsets. The intention was mostly to prevent cheating at the puzzles, but also to prevent opening the puzzles in the map editor. Not an ultra-secure encryption requirement, but I did make it scramble the file format, so that there was no easy way to unlock the maps by fiddling with it in a text editor.
I thought I was being quite devious with various “scrambling” tricks, essentially re-arranging the bytes of the file with an algorithm only I knew about. Of course this is not proper encryption at all, but my naive younger self believed it would be enough to prevent anyone decoding it.
At some point Gerald J Holdsworth figured out my file format. He’s created a repton map decoding tool, and even documented exactly how the scrambled file format works here! (page 41 “HW Repton 3”)
“Each screen map is interlaced with each other, and the passwords, transporters, time limits and visible flag are interlaced with the map data. Also, the column and row order is interlaced. In addition, it is encoded with the lock password and a counter.”
Oh yes! I remember doing that! I remember thinking I was being very sneaky. I never imagined someone would painstakingly figure out this encoded byte arrangement! How did he do it? I assume he did it with “known plain text” attacks, or in this case by crafting known repton map designs. This is generally the fatal flaw if you take this approach of trying to just algorithmically scramble the file a lot. So remember, if you’re locking up some more important data, don’t do that! Use actual encryption.
Even so I imagine it took Gerald quite some effort figure this out. I’m deeply impressed, partly just because it’s cool to see someone sufficiently motivated to access my Repton map designs! I’m also glad that he did, because of what happened next.
Repton 3?
…rewind to the 1980s
I remember visiting our older cousin, who showed me Repton 3 on their BBC micro. I was instantly enthralled, and a little too obsessed by this game. It’s mostly a puzzle game, with a bit of speed and dexterity required at times, and coming with its own map and sprite editor. Eventually we got our own BBC micro, and I played Repton 3 a lot.
…Fast-forward to 1998.
The BBC micro was broken, and I hadn’t been able to play Repton 3 in years, but home from university that summer I decided I needed to re-create it to play on the PC. I think I was trying to push my Visual Basic programming skills. Compared to BASIC I had learned on my Acorn, this was a proper language on my dad’s PC. A poor choice as games development language, but that didn’t put me off. I figured out a way of flipping images on a grid of image objects to create the game screen with a reasonable, if a little jerky, perception of motion. And so with an outpouring of youthful programming energy I created a faithful reproduction of Repton 3 entirely from memory, including a map editor.
And then I designed some map puzzles to play on it. Designing the puzzles takes a lot longer than playing the puzzles. A very interesting exercise in itself. I remember spending weeks and weeks devising devilish puzzles. It was probably a bigger effort than the programming. I created a complete set of eight maps for “easy” and “main”. I never finished making my “hard” levelset.

I’m particularly proud of this beast. Level 5 on the “main” set. This is probably the hardest of my maps. The rocks start in a striking diagonal arrangement, so that if you drop too many too early, then the spirit will be released at the top of the map, causing the crown to be blocked. (That’ll make more sense if you give it try)
Around the same time, or maybe a year or so later, I designed a website for it. You may have noticed the funny little repton 3 sub-site of my website (This is looking pretty retro itself nowadays. The repeating-pattern background has a bit of a 1990s geocities vibe!)
…since then
More recently (well this millennium at least), some people completed my puzzles and let me know. Not many. I’d love for more people to try it. But part of the problem is that even back then, the .exe file download doesn’t work very well. The version of Visual Basic I had used produced an outdated 16bit binary which started to be harder to get running on newer windows, and I haven’t had a windows machine in a while now, but…
…more recently
I became aware that the BBC could be emulated on a PC well enough to play the original repton 3. In fact BeebEm has apparently existed since 1994. I probably wouldn’t have bothered with any of this had I known! And it demotivated me to do anything to try to rescue my old codebase into some more useable form. These days you can even emulate a BBC micro to play the original Repton 3 in your browser! Sadly I couldn’t play my own maps online until…
…in 2025
Just recently my son was browsing projects on scratch. Scratch is a whole other story. A visual programming environment. It’s quite fun, and it’s also impressive that the site has so many people sharing projects on every imaginable topic. Lots of weird stuff created by kids, but also lots of surprisingly professional game creations. Somehow my son came across Repton 3 created by colinmacc …with me getting a mention in the credits! Why? Because you can play my map designs on there!
So I recently enjoyed a bit of repton-nerdy discussion with colinmacc. Goodness knows how he used something like scratch to develop this. It’s an impressive piece of work. But he also confirmed he’d been able to make use of Gerald J Holdsworth’s decoding work (described above) to bring in my map designs. We discussed some quirky aspects of the original game which I had misremembered when making mine. These past few weeks I’ve played through all these maps again. I’m delighted that my deviously designed Repton maps are now more readily available.
So I guess there’s an open data lesson here. In addition to “Don’t roll your own encryption” we could say “Don’t expend effort locking away data which could just be open!”. I’m much more of an open data warrior, than I was at age 19, but even then I presumably weighed up pros and cons of bothering with encrypting. I was hoping to see lots of people try my maps, and I wanted a way for them to prove that they’d solved the puzzles fair and square. That was potentially fun, and it happened a tiny bit, but you know what’s more fun? Open data! After all my effort encrypting, causing Gerald lots of effort to decode it, the final result is that colinmacc was able to bring this data into his software, making my maps more widely and easily available. And that’s way more fun! So here we go:
Click here to try it now! (Click the green flag to run) and let me know if you can complete my ‘easy’ and ‘main’ scenarios.